目录
ChatGPT 的巨大成功激发了越来越多的开发者兴趣,他们希望利用 OpenAI 提供的 API 或者私有化模型,来开发基于大型语言模型的应用程序。尽管大型语言模型的调用相对简单,但要创建完整的应用程序,仍然需要大量的定制开发工作,包括 API 集成、互动逻辑、数据存储等等。
为了解决这个问题,从 2022 年开始,许多机构和个人相继推出了多个开源项目,旨在帮助开发者们快速构建基于大型语言模型的端到端应用程序或工作流程。其中一个备受关注的项目就是 LangChain 框架。
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
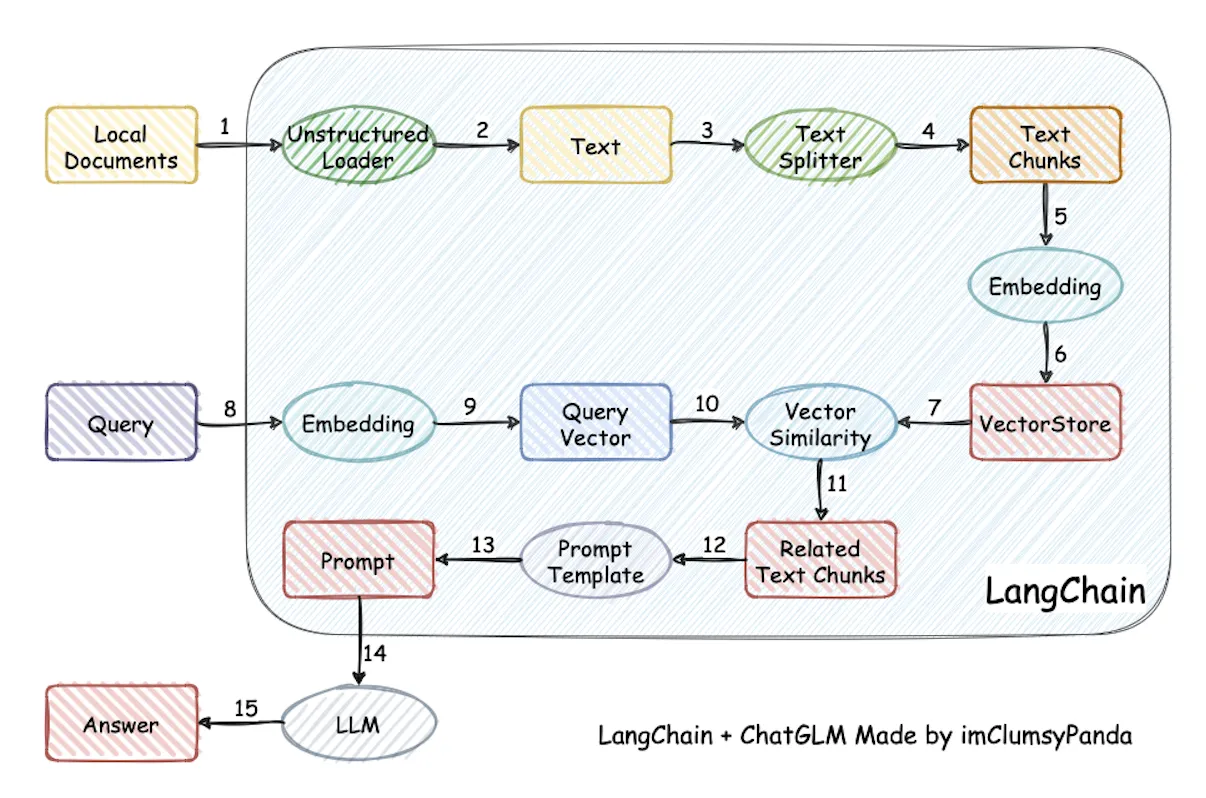
什么是unstructed Loader?
"Unstructured Loader" 可以翻译为 “非结构化加载器”。
这个术语通常用于数据处理或机器学习领域,指的是一种加载和处理非结构化数据(如文本、图片、音频、视频等)的工具或系统。非结构化数据没有预定义的数据模型或格式,通常需要更灵活的处理方式。
什么是Text Splitter?
Text Splitter(文本分割器)是一种工具或算法,用于将一段连续的文本分割成更小的部分,通常是为了进一步处理、分析或提取信息。文本分割器的应用非常广泛,可以用于自然语言处理(NLP)、数据预处理、文本分析等场景。
Text Splitter的常见应用:
-
自然语言处理(NLP)
- 在NLP中,文本分割器用于将大段文本划分成句子、段落、单词或者其他有意义的单元。这样做有助于模型更好地理解文本的结构和语义。
- 句子分割:将一段文本按句子划分,这对于机器翻译、文本生成等任务至关重要。
- 单词分割:在一些语言中(比如中文),词与词之间没有明确的分隔符,因此需要进行词语分割,以便进行语义分析。
-
文档处理
- 当需要从一篇长文档中提取特定的信息或进行文档摘要时,文本分割器可以把文档分割成较小的部分,如段落、章节或语义单元,使得处理更高效。
-
数据预处理
- 在数据清洗和预处理阶段,文本分割器有时用于去除冗余的内容、按特定规则划分文本,以便为后续的机器学习模型训练做准备。
-
文本索引与搜索
- 文本分割器可以将长文本分割为较小的片段或段落,以便更快速的进行索引、搜索和信息检索。
常见的文本分割方法:
-
按空格或标点符号分割
- 最常见的方法是按照空格、逗号、句号等标点符号进行分割。这种方法适用于英语等语言,其中单词和标点符号之间有明显的分隔符。
-
正则表达式
- 通过使用正则表达式,可以根据特定的模式来拆分文本。例如,可以按特定的字符长度、单词边界或者特定的符号来划分文本。
-
基于语言的分割
- 对于某些语言(例如中文或日语),文本分割器需要更复杂的算法,因为这些语言的单词之间没有空格或明显的分隔符。常用的方法包括基于词典的分割或使用机器学习模型进行分词。
-
按语义分割
- 语义分割不单纯依赖于标点符号或空格,而是根据文本的含义进行分割。例如,可以根据文章的主题或话题划分段落。
典型应用实例:
-
文档摘要
- 长篇文档需要被分割成较小的部分,模型可以先处理每个小部分,然后生成相应的摘要。
-
文本生成与翻译
- 在机器翻译中,文本被分割成句子或词汇,逐步进行翻译。类似地,在文本生成任务中,模型会根据文本分割的结果逐句或逐段生成内容。
-
情感分析
- 在进行情感分析时,文本可以按句子或短语进行分割,这样有助于精确判断每个部分的情感倾向。
总结:
Text Splitter 是一种在文本处理过程中,将长文本划分为较小、更易于处理的单元的工具或算法。这在很多文本分析、数据预处理、NLP模型训练等领域中都非常重要。通过有效地分割文本,可以提高分析效率和准确性,为后续的任务打下基础。
什么是TextChunks?
TextChunks(文本块)通常指将一段较长的文本划分为更小的、具有语义或结构意义的部分。这些块(Chunks)可以是段落、句子、短语、关键词等,具体取决于应用场景和分割标准。TextChunks的目的是通过将长文本分成多个较小的单元,使得处理、分析和理解文本变得更加高效。
TextChunks的应用场景
-
自然语言处理(NLP)
- 在NLP中,TextChunks常用于处理长文本,使得每个块(chunk)都能被单独分析。这可以帮助模型理解文本的结构,并在进行文本分类、情感分析、命名实体识别等任务时,提升精度和效率。
-
文本分析和信息提取
- 在信息提取任务中,文本被划分为多个小块,模型或系统可以从每个TextChunk中提取关键信息。比如,在问答系统中,TextChunks有助于将长文档分割成段落或句子,以便快速定位相关的信息。
-
文档检索
- 对于长文档,TextChunks可以使得检索过程更高效。通过将文档切分成小的块,搜索引擎可以更精确地索引每个块,从而提高搜索结果的相关性。
-
文本生成
- 在生成任务(如文本生成、机器翻译)中,TextChunks可以帮助模型更好地理解每个文本块的上下文和意义,从而生成更连贯的内容。
TextChunks的常见划分方法
-
按句子划分
- 将文本按句子进行切分,每个句子是一个独立的文本块。这种方法简单且常用于大多数文本分析任务,特别是在情感分析和机器翻译中。
-
按段落划分
- 将文本按段落切分,每个段落作为一个TextChunk。这种方法适用于需要分析文档结构或层次关系的任务,例如文档分类和摘要生成。
-
基于主题或语义分块
- 将文本根据主题或语义进行切分,每个TextChunk可能代表一个单独的主题或概念。此方法在文档摘要、主题建模和语义分析中尤为常见。
-
按固定长度划分
- 有时根据字符数或单词数进行切分,比如每个TextChunk包含固定数量的字符或单词。这种方法在处理极长文本时很有用,尤其是在训练模型时。
-
基于正则表达式
- 使用正则表达式对文本进行分割,能够根据复杂的模式(如特定的标点符号、词汇或结构)来划分TextChunks。
TextChunks的优点
-
更高效的处理
- 通过将长文本分割为更小的块,可以将每个块作为独立单元进行处理,避免了处理整个文档时可能遇到的计算瓶颈。
-
增强的语义分析
- 每个TextChunk通常包含较为完整的语义信息,帮助系统更好地理解文本的内容,特别是在语义分析和情感分析等任务中。
-
改善模型表现
- 在训练模型时,将文本切分成合理的TextChunks可以帮助模型捕捉到更多的上下文信息,提升其在不同任务中的表现。
-
提高文本搜索的精确度
- 在文档检索中,TextChunks可以使搜索系统更精准地定位到相关的信息片段,而不仅仅是简单地返回整个文档。
总结
TextChunks指的是将长文本拆分成多个小的、有意义的部分(块),这些部分可以是句子、段落、主题单元等。这种方法常用于自然语言处理、信息检索、文本生成等领域,旨在提高文本处理的效率和效果。通过合理的文本分割,可以使得模型更好地理解文本,进而提高各类任务的处理效果。
什么是Vector Similarity?
Vector Similarity(向量相似度)是衡量两个向量之间相似程度的度量方法。在自然语言处理(NLP)、信息检索、推荐系统等领域中,向量相似度被广泛应用,用来比较不同数据点(如文本、图像、用户行为等)之间的相似性。
为什么需要Vector Similarity?
在许多机器学习和数据分析任务中,我们通常会将数据(例如,文本、图像或其他对象)转换为向量表示(如词嵌入、特征向量等)。一旦数据被表示为向量,计算它们之间的相似度就成为了比较和理解这些数据的核心操作。向量相似度帮助我们判断哪些数据点是相似的,哪些是不相似的。这对于搜索、分类、聚类等任务尤为重要。
常见的向量相似度度量方法
-
余弦相似度(Cosine Similarity)
余弦相似度是最常用的向量相似度度量方法之一。它衡量的是两个向量之间的夹角,而非它们的大小(即向量的长度)。两个向量的余弦相似度值越接近1,表示它们越相似;越接近-1,表示它们越不相似。余弦相似度的公式为:
[ \text{Cosine Similarity} = \frac{A \cdot B}{|A| |B|} ]
其中,(A \cdot B) 是向量 (A) 和向量 (B) 的点积,(|A|) 和 (|B|) 分别是向量 (A) 和向量 (B) 的欧几里得范数(长度)。
- 优点:对向量的长度不敏感,特别适用于文本数据等稀疏向量的比较。
- 应用:常用于文本相似度计算、信息检索、推荐系统等。
-
欧几里得距离(Euclidean Distance)
欧几里得距离是计算两个向量之间的直线距离。它的计算公式为:
[ \text{Euclidean Distance} = \sqrt{\sum_{i=1}^{n} (A_i - B_i)^2} ]
其中,(A_i) 和 (B_i) 分别是向量 (A) 和向量 (B) 的第 (i) 个元素。
- 优点:计算简单直观。
- 缺点:对向量的尺度敏感,当向量的大小差异较大时,欧几里得距离的结果可能受到较大影响。
- 应用:常用于聚类分析、分类问题、机器学习中的特征距离计算。
-
曼哈顿距离(Manhattan Distance)
曼哈顿距离也叫“税icab”距离,是计算两个点之间在直角坐标系下的绝对差之和。公式如下:
[ \text{Manhattan Distance} = \sum_{i=1}^{n} |A_i - B_i| ]
- 优点:对于高维数据或稀疏数据较为有效,尤其是在某些特征维度上存在较大差异时。
- 应用:常用于文本挖掘、模式识别和一些机器学习算法中。
-
杰卡德相似系数(Jaccard Similarity)
杰卡德相似度用于衡量两个集合的相似性,特别适用于二值(0/1)数据的比较。对于两个集合 (A) 和 (B),它的计算公式为:
[ \text{Jaccard Similarity} = \frac{|A \cap B|}{|A \cup B|} ]
其中,(|A \cap B|) 表示集合 (A) 和 (B) 的交集的大小,(|A \cup B|) 表示集合 (A) 和 (B) 的并集的大小。
- 优点:适用于集合或二元数据的相似度计算。
- 应用:常用于集合的相似性度量,如推荐系统中的用户兴趣相似度计算。
-
皮尔逊相关系数(Pearson Correlation)
皮尔逊相关系数用于衡量两个向量之间的线性相关性。其计算公式为:
[ \text{Pearson Correlation} = \frac{\sum_{i=1}^{n} (A_i - \bar{A})(B_i - \bar{B})}{\sqrt{\sum_{i=1}^{n} (A_i - \bar{A})^2} \cdot \sqrt{\sum_{i=1}^{n} (B_i - \bar{B})^2}} ]
其中,(\bar{A}) 和 (\bar{B}) 是向量 (A) 和 (B) 的均值。
- 优点:能够捕捉线性关系。
- 应用:常用于推荐系统、统计分析和变量之间关系的探讨。
向量相似度的应用
-
文本相似度计算
在自然语言处理中,将文本转换为向量(如词嵌入、TF-IDF等),然后使用向量相似度度量方法来判断文本之间的相似性。这在信息检索、问答系统、机器翻译等任务中非常重要。 -
推荐系统
在推荐系统中,用户的行为或兴趣常常被表示为向量,利用向量相似度方法可以为用户推荐相似的产品、电影、音乐等。 -
聚类和分类
向量相似度常用于聚类算法(如K-means)和分类算法(如KNN)中,用于判断数据点之间的相似性,从而进行聚类或分类。 -
图像和音频检索
图像和音频常常被表示为特征向量,计算相似度可以用于查找相似的图像或音频片段。
总结
Vector Similarity是通过计算向量之间的相似度来比较数据点之间的关系,广泛应用于文本分析、推荐系统、数据挖掘等领域。不同的相似度度量方法(如余弦相似度、欧几里得距离等)适用于不同类型的任务,选择合适的相似度度量对于任务的效果和效率至关重要。
什么是Prompt Template?
Prompt Template 是在与自然语言处理(NLP)模型交互时,提前设计好的结构化格式或“框架”,用于构建输入提示(Prompt)。这种模板可以帮助用户通过一些预设的变量或占位符,更高效地生成输入,从而更好地引导模型生成期望的输出。
1. 为什么使用Prompt Template?
在与大型语言模型(如 GPT)互动时,输入的提示语(Prompt)对于输出的质量至关重要。一个精心设计的提示可以引导模型生成高质量、相关性强的答案。Prompt Template 通过结构化的方式,帮助用户避免每次都从零开始编写提示,并且可以根据不同任务灵活调整。
2. Prompt Template的基本结构
Prompt Template 通常由一个或多个占位符组成,这些占位符可以是变量或需要用户填写的部分。模板中可以包含指令、问题、背景信息或上下文。常见的 Prompt Template 格式包括:
- 指令 + 变量/占位符
- 问题 + 变量/占位符
- 情境设定 + 任务描述
例如,假设你正在使用语言模型来生成某个主题的文章或解释,Prompt Template 可以是:
请根据以下主题写一篇简短的文章:{主题}
其中 {主题} 是一个占位符,可以根据具体的需求替换成不同的主题。
3. Prompt Template的常见应用
-
问题生成(Question Generation)
- 模板:
请给出关于{主题}的3个问题。 - 用途:帮助用户生成与特定主题相关的问题列表,适用于教育、测验、内容生成等场景。
- 模板:
-
情境模拟(Scenario Simulation)
- 模板:
假设你是{角色},你会如何应对以下情况:{情境描述}? - 用途:通过模拟特定情境,帮助模型生成角色扮演式的对话或决策。
- 模板:
-
文章/内容生成
- 模板:
请根据以下标题写一篇简短的文章:{文章标题} - 用途:用于生成文章、博客、报告等内容,适合自动化写作和内容创作。
- 模板:
-
文本总结
- 模板:
请总结以下内容:{长文本} - 用途:从长篇文本中提取出关键信息,适合于文档摘要、新闻摘要等场景。
- 模板:
-
情感分析
- 模板:
请分析以下文本的情感倾向:{文本} - 用途:适用于情感分析任务,判断文本中的情感态度(如正面、负面、中立)。
- 模板:
4. Prompt Template的优化
虽然Prompt Template 是一个非常有效的工具,但要确保它能够产生高质量的输出,还需要注意以下几点:
-
明确的目标:确保模板能够清晰表达任务要求。越是明确的任务描述,越能引导模型生成相关且有用的答案。
-
上下文设定:根据任务的不同,可以在模板中加入背景信息、角色设定、限制条件等,帮助模型理解生成的具体场景。
-
变量的灵活性:确保模板中的变量能够根据不同的输入调整,而不会导致模型的输出偏离目标。
5. 示例
1. 情景描述与问答:
模板:
你是一个{职业},请根据以下情境回答问题: 情境:{情境描述} 问题:{问题}
例如:
你是一个医生,请根据以下情境回答问题: 情境:一位病人刚刚做了手术,他感到有些不适,想知道该如何缓解疼痛。 问题:请提供一些建议,帮助病人缓解手术后的疼痛。
2. 教育用途:
模板:
请为以下主题提供一个详细的解释:{主题}
例如:
请为以下主题提供一个详细的解释:量子物理
3. 内容生成:
模板:
请写一篇关于{话题}的文章,要求包括以下部分: - 简介 - 主要观点 - 结论
例如:
请写一篇关于人工智能的文章,要求包括以下部分: - 简介 - 主要观点 - 结论
6. 高级用法:动态模板
在实际应用中,有些 Prompt Template 可能需要根据外部数据源或用户的输入动态生成。例如,结合数据库查询或用户交互,模板中的占位符会被实时替换:
- 输入:用户提供了电影名称。
- 模板:
请为电影{电影名称}写一篇影评。 - 输出:
请为电影《肖申克的救赎》写一篇影评。
总结
Prompt Template 是一个灵活、结构化的框架,能够帮助用户快速生成有效的提示,从而获得更好的模型输出。通过精心设计的模板,可以使与语言模型的交互更加高效,应用更加广泛。
LangChain的核心组件

LangChain 正式发布了其稳定版本 v0.1.0
LangChain的生态

本文作者:Eric
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!