目录
EverMemOS:企业级智能记忆系统
LLM训练大致分为三个阶段,Pre-Training学知识,SFT学说话,Post-Training学思考。这样的LLM用作问答没有问题,但是用作AI助理或者家庭机器人就有一个非常致命的缺点:LLM没有记忆,每次对话默认从零开始。除非附带历史信息,LLM不会记得你的任何信息,无法提供个性化、连贯的服务。
EverMemOS: Enterprise-grade intelligent memory system LLM training is roughly divided into three stages: Pre-Training to learn knowledge, SFT to learn to speak, and Post-Training to learn. There is no problem with such LLMs being used as question answerers, but they have a very fatal drawback when used as AI assistants or home robots: LLMs have no memory, and each conversation starts from scratch by default. LLMs will not remember any of your information unless accompanied by historical information and cannot provide personalized, coherent services.
LLM记忆的设计模式
主要分为两类:第一类是模拟人类的记忆方式(来自论文CoALA),第二类是从计算机工程的角度设计(Letta提出)。
Design patterns for LLM memory There are two main categories: the first is to simulate the way humans remember (from the paper CoALA), and the second is to design from the perspective of computer engineering (proposed by Letta).
拟人化记忆的四种记忆类型:
- 临时记忆:当前对话的内容,对应到LLM就是context,LLM的context的长度通常是256K tokens,Gemini则能达到1M tokens。
- 事实类记忆:这类记忆通常对所有人都是一样的。对于人类来说,就是人学到的知识和事实,例如水在0度结冰、小明不喜欢吃香菜;对于LLM,就是关于用户的信息,例如用户是男性、名字叫Gorden。
- 经历类记忆:这类记忆则因人而异。对于人类来说,就是发生过的事,例如上个周末去了公园、吃了火锅;对于LLM来说,过去的聊天记录提炼出来的总结都可以算作这类记忆,例如用户提问了如何减肥。
- 技能类记忆:对人类来说,就是如何开车这种学会后不必再思考、形成了本能的技能;对于LLM来说,就是system prompt,例如让LLM回复时必须使用Json格式。(例如http://CLAUDE.md)
The four types of memory of anthropomorphic memory: · Temporary memory: The content of the current conversation corresponds to the LLM as the context, the length of the LLM context is usually 256K tokens, and Gemini can reach 1M tokens. · Factual memory: This type of memory is usually the same for all people. For humans, it is the knowledge and facts that people have learned, such as water freezing at 0 degrees, Xiao Ming doesn't like to eat coriander; For LLMs, it is information about the user, such as whether the user is male and given the name Gorden. · Experiential memory: This type of memory varies from person to person. For humans, it is what has happened, such as going to the park and eating hot pot last weekend; For LLMs, summaries extracted from past chat records can be counted as such memories, such as when a user asks how to lose weight. · Skill memory: For humans, it is how to drive, which is a skill that does not have to think and form instincts after learning; For LLMs, it's a system prompt, for example, the LLM must use Json format when replying. (e.g. http:// CLAUDE.md)
计算机工程出发的记忆类型:
- 消息缓冲区:即当前对话内容,对应拟人化记忆的临时记忆。
- 核心记忆:由智能体维护的事实类记忆,但是对于当前对话,只取有关联的事实用作上下文。
- 历史对话记录:包括所有完整的历史对话记录,在必要是搜索使用。
- 压缩类记忆:存储在外部的、经过提炼且加了索引的知识和记忆,通常用向量数据库存储,在查询后把信息放到上下文中。比历史对话记录更高效。
Types of memory from computer engineering: · Message buffer: The current conversation content corresponds to the temporary memory of anthropomorphic memory. · Core memory: A factual memory maintained by the agent, but for the current conversation, only relevant facts are used as context. · Historical Conversation History: Includes all complete historical conversation records, searched and used if necessary. · Compressed memory: External, refined and indexed knowledge and memory, usually stored in a vector database, and the information is put into context after querying. More efficient than historical conversation records.
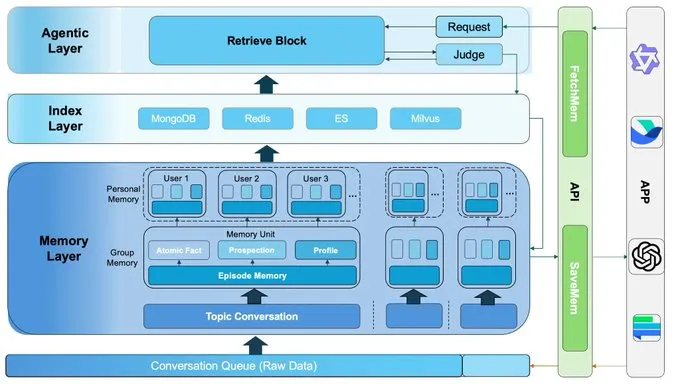
EverMemOS主要使用的是拟人化记忆模式,结合了工程类记忆的效率实践,设计了多层次、多类型的记忆结构。存储记忆的大致流程是:
- 识别对话中的关键信息,提炼成记忆单元;
- 按对话主题、对话用户,与之前的记忆整合,梳理出脉络和用户画像;
- 建立记忆的关键词和索引,用于快速召回;
EverMemOS mainly uses anthropomorphic memory mode, combined with the efficiency practice of engineering memory, and designs a multi-level and multi-type memory structure. The general process of storing memories is: 1) Identify key information in the dialogue and refine it into memory units; 2) According to the dialogue topic and dialogue users, integrate with the previous memory, sort out the context and user portrait; 3) Establish memorized keywords and indexes for quick recall;
如何调用记忆
调用记忆的核心挑战是如何避免因为记忆过多、查询过慢导致响应时间变长。对于需要快速响应的对话,EverMemOS直接使用RRF融合算法(Reciprocal Rank Fusion);对于复杂的场景,Agent会生成2-3个互补查询,补全缺失的信息,提升复杂问题的覆盖面,然后并行查询出需要使用的记忆。
How to call memory The core challenge of calling memory is how to avoid long response times due to too many memories and slow queries. For conversations that require a quick response, EverMemOS directly uses the RRF Rank Fusion algorithm. For complex scenarios, the agent generates 2-3 complementary queries to complete the missing information, improve the coverage of complex problems, and then query the memories that need to be used in parallel.
召回多层次的记忆后,再与当前对话内容拼接,整合成完整的上下文,给出最终的回复。一个典型的例子是你让AI给你推荐饮食,AI可以联想到你前几天做了牙科手术,从而有针对性的调整建议。
After recalling the multi-level memory, it is then spliced with the current conversation content and integrated into a complete context to give the final response. A typical example is when you ask AI to recommend a diet for you, which can be associated with the fact that you had dental surgery the other day to make targeted adjustments.
通过 "结构化记忆 → 多策略召回 → 智能检索 → 上下文推理" 的记忆和召回路径,EverMemOS在LoCoMo评测里达到了 92.4% 的推理准确率**,**为目前最佳。长时间的记忆里、高准确率的召回率,是AI助理和AI机器人的必需能力,2025年是Agent的元年,2026会成为记忆的元年。
Through the memory and recall paths of "Structured Memory→ Multi-Policy Recall→ Intelligent Retrieval →Contextual Reasoning", EverMemOS achieved an inference accuracy of 92.4% in the LoCoMo evaluation, which is the best at present. In long-term memory, high accuracy recall is a necessary ability for AI assistants and AI robots, 2025 is the first year of Agent, and 2026 will become the first year of memory.
本文作者:Eric
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!