目录
如何分析接口响应的问题?
1. 背景
公司项目中,某个业务接口会出现,100次的请求,有1-2次的请求速度会非常慢,领导有以下要求:
- 要能够监控后端接口,及时发现请求慢的接口是哪些?
- 找到请求慢的接口之后,需要对其接口进行详细分析,这个过程中要可以直观看出哪些函数调用花费的时间是多少?
我能够想到的:
- 如何快速且高效率解决这个问题?要求:可以快速集成到项目中,不会修改太多的地方
- 因为接口分析是会消耗很大的,一般不推荐在生产环境中,在能够复现问题的情况下,如何不影响系统主要的系统功能
- 模块化处理,可以增加到其他的项目中。例如ai、chatbi等等
- 关于监控,在flask加入Metrics,利用grafana和Prometheus进行监控。目前已经实现,可统计接口的响应时间
技术栈:
- flask + Mysql
1.1 平均接口响应时间参考内容
2. 可实现方法
监控类:
- promtheus 和 grafana
函数分析类:
- snakeviz + cProfile
- vprof 适合单个函数,开始-有结束的函数文件,不适合接口类
- gprof2dot 没有实验成功,比较麻烦
- pycallgraph 待实验
3. 实践
3.1 函数分析使用
shellpip install cProfile, snakeviz
主要代码:
python# 性能监视装饰器
def profile_decorator(func):
import cProfile
import pstats
def wrapper(*args, **kwargs):
profiler = cProfile.Profile()
profiler.enable()
result = func(*args, **kwargs)
profiler.disable()
# stats = pstats.Stats(profiler).sort_stats('tottime')
# stats.print_stats()
profiler.dump_stats('profile_results.prof')
return result
return wrapper
根据导出的文件,查看分析可视化
shellsnakeviz profile_results.prof
3.2 监控使用
启动Prometheus和grafana
yamlversion: '3'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
restart: always
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- ./grafana_data:/var/lib/grafana # 添加持久化存储
depends_on:
- prometheus
volumes:
grafana_data:
prometheus_data:
启动命令:
shelldocker-compose up -d
如何在flask配置metrics
在接口增加白名单,跳过登录:
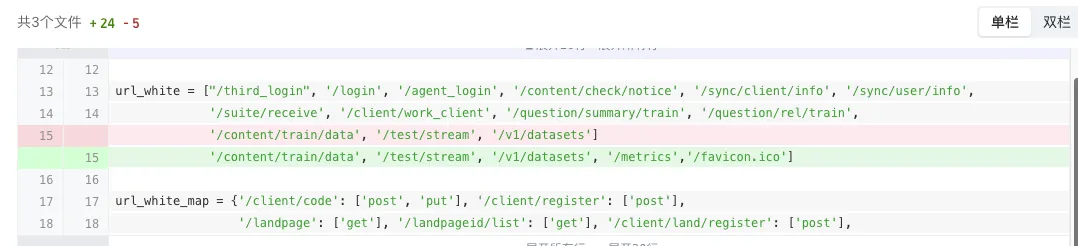
初始化:
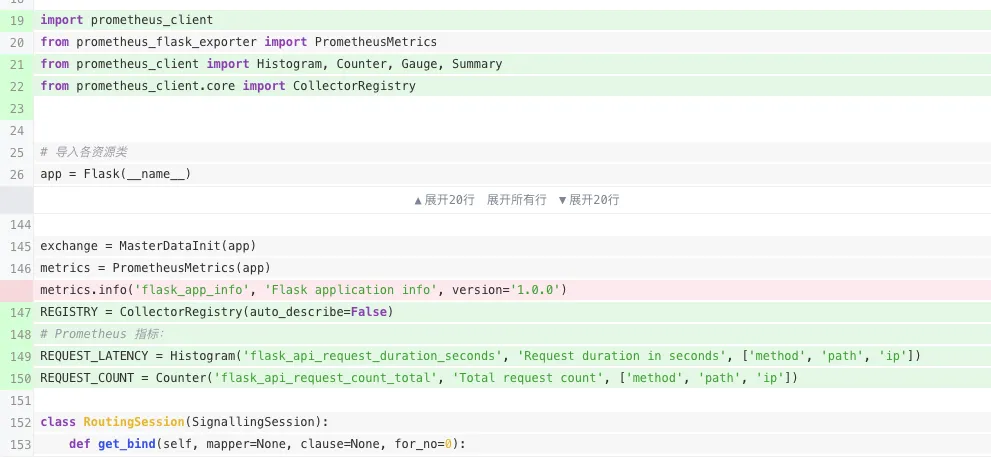
在请求和响应增加钩子函数,来监控:
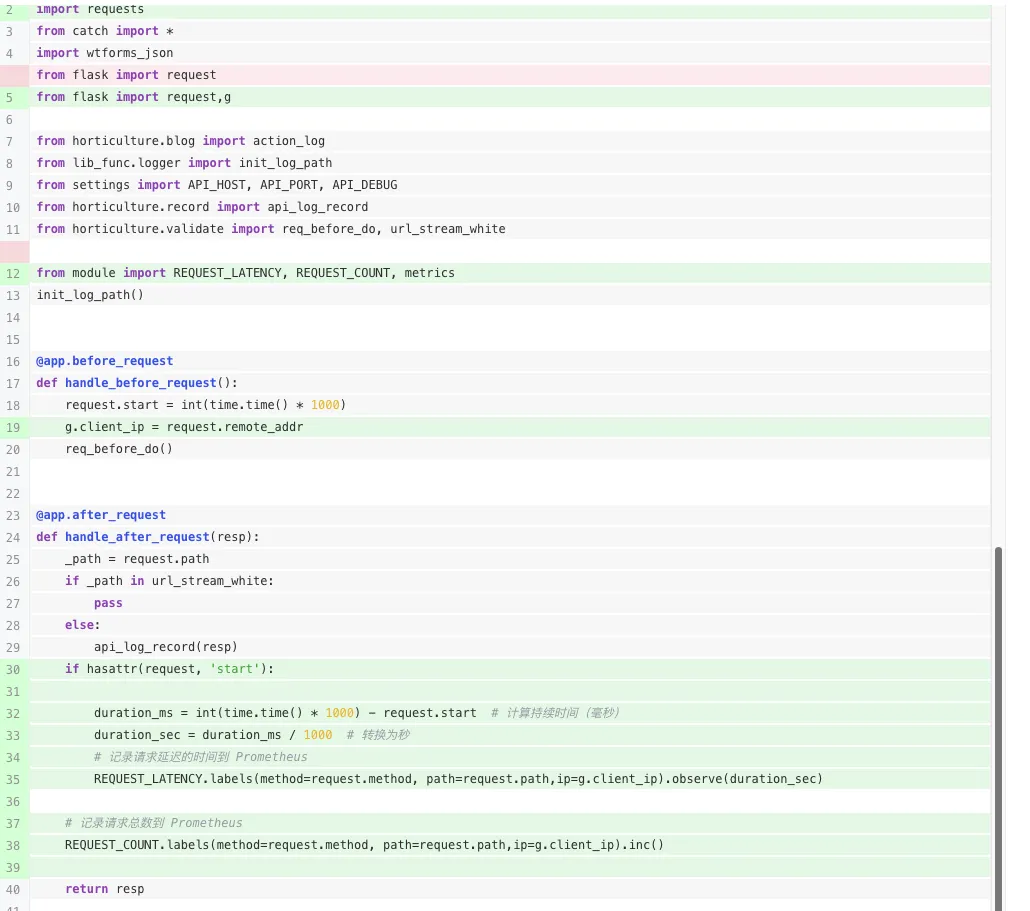
3.3 模拟分析
背景:分析获取列表页的响应速度
查看F12 接口响应时间

apipost响应时间, 同样的用户和接口:
snakeviz分为两种可视化样式:
- icicle :冰柱
- sunburst: 旭日形
在 icicle 可视化样式中,函数由矩形表示
根函数是最顶部的矩形,它调用的函数位于其下方,然后是这些调用的函数位于其下方,依此类推。
在函数中花费的时间量由矩形的宽度表示。横跨大部分可视化效果的矩形表示占用其调用函数大部分时间的函数,而细长矩形表示几乎不使用任何时间的函数
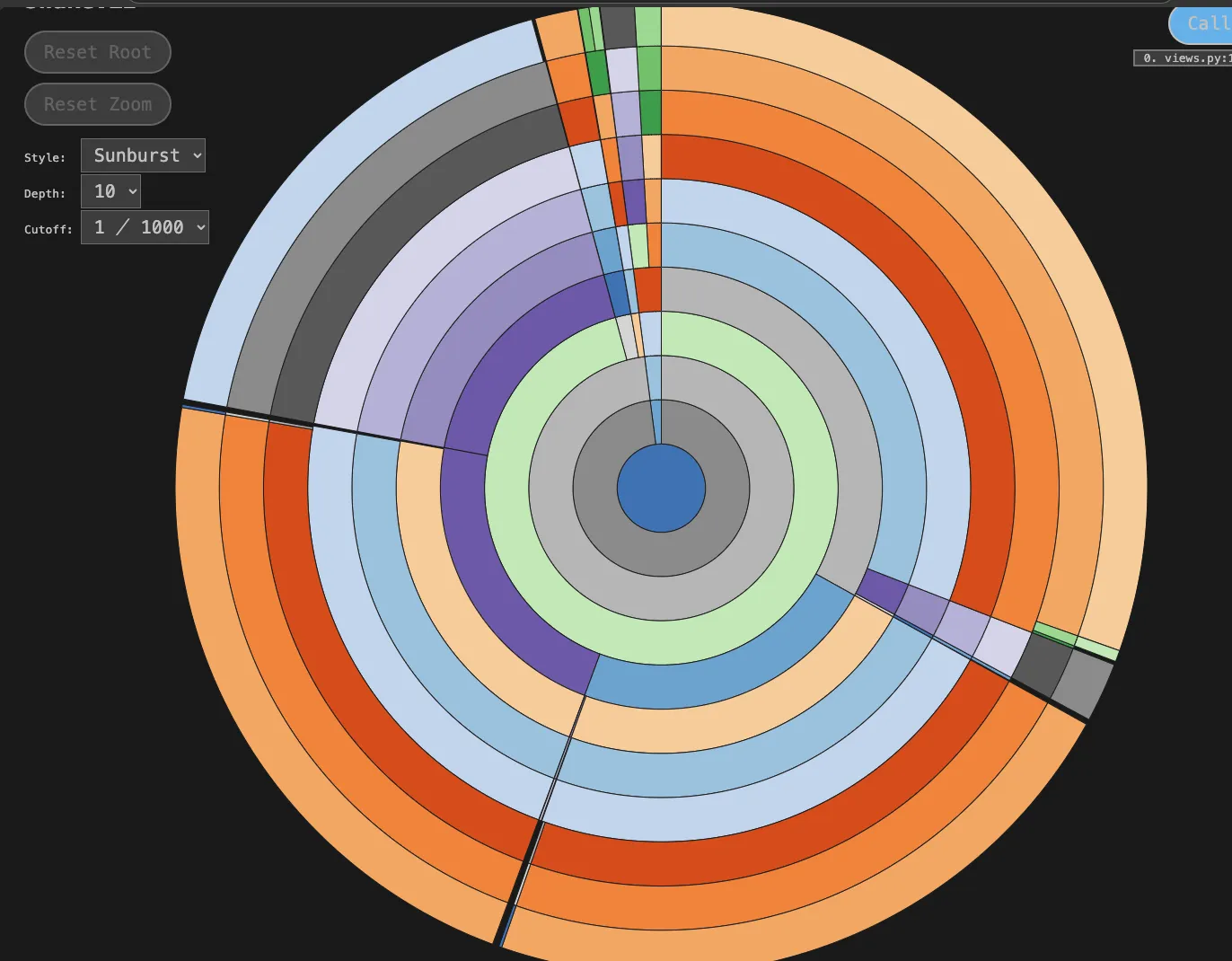
在旭日形可视化样式中,函数表示为圆弧。
根函数是中间的一个圆圈,它调用的函数,然后是这些函数调用的函数,依此类推。
在函数内花费的时间由圆弧的角度范围(它绕圆走多远)表示。
将大部分时间环绕圆圈的圆弧表示占用其调用函数大部分时间的函数,而细圆弧表示几乎不使用任何时间的函数。
 功能信息:
功能信息:
- name: 函数名称
- Cumulative Time: 函数中花费的总累积时间(以s为单位),占程序总运行时间的百分比
- file: 定义函数的文件的名称
- line: 定义函数的行号
- directory: 文件目录
注意:对于某些内置函数,文件名、行号和目录将分别为 '~'、0 和空白。
“Depth(深度)”下拉菜单控制 SnakeViz 在构建可视化时进入调用堆栈的深度。在你通过单击调用堆栈中更深处的 new function 进行放大之前,不会显示低于此深度的任何内容。增加显示深度将一次显示更多配置文件,但构建和显示图表可能需要更长的时间
“Cutoff” 下拉菜单控制占用其父级累积时间的函数的显示。如果函数的累积时间除以其父函数的累积时间小于当前设置的截止时间,则将显示该函数,但不会显示其任何子函数。设置较大的截止可能会显示较少的配置文件,但可以加快可视化的构建和渲染速度。
缩放和调用堆栈(右上角的CallBack):
单击一个函数将缩放可视化效果,使该函数成为新的根,并允许您放大配置文件的不同部分。
单击冰柱可视化的顶部栏或旭日形的中心将缩小一个级别,单击“重置缩放”按钮将使可视化返回到其最缩小的状态。
可视化的右侧是一个 “Call Stack” 按钮。
单击此按钮将展开一个列表,其中显示导致当前可视化根的所有函数,根函数位于列表底部。
调用堆栈可用于在放大配置文件时确定自己的方向。再次单击 “Call Stack” 按钮以隐藏列表。
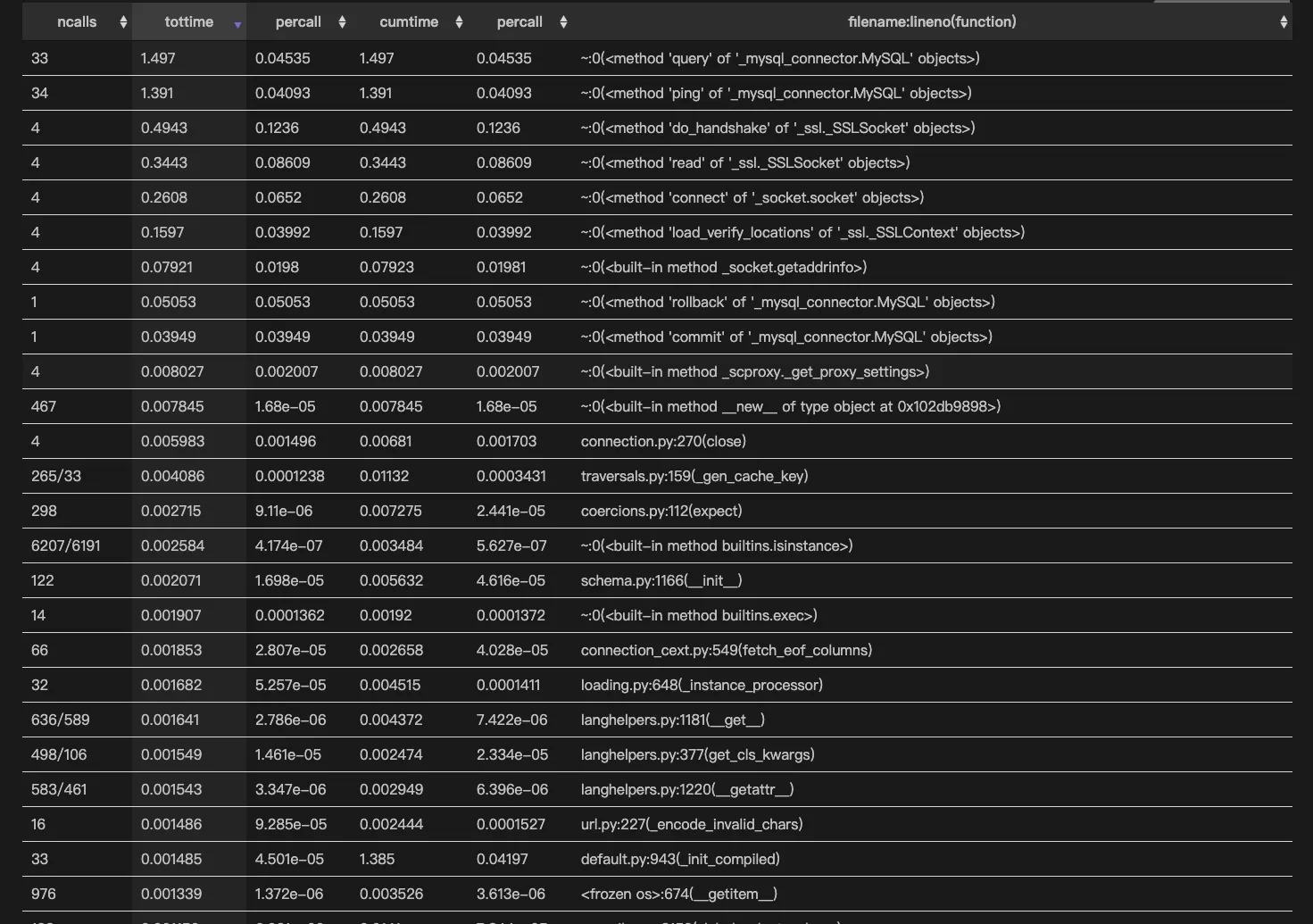
统计表格的含义:
- 该表包含每个调用的唯一函数一行。 从不同位置对同一函数的调用都分组为 一行。 cProfile用户手册
ncalls: n调用,对函数的的调用总数。如果有两个数字,则表示函数递归,第一个是调用总数,第二个是原始(非递归)调用的次数tottime: 在函数中花费的总时间,不包括调用子函数所花费的时间percall: tottime/ ncalls。它反映了函数自身代码的平均执行效率。cumtime: 在此函数和所有子函数中花费的累计时间percall: cumtime/ ncalls。它反映了函数及其子函数的平均执行效率。filename: 定义函数的文件名和行号,以及函数的名称
单击表中的函数将使该函数成为可视化的根。单击可视化左侧的“重置根”按钮会将可视化重置为 SnakeViz 启动时确定的原始根功能。
4. 感悟
- 使用时候,按照cumtime进行排序,然后从上往下进行分析,这种是本身函数执行很快,但是子函数执行非常慢
- 对于重复调用次数多的,建议采用批量处理
- 对于数据库操作比较多的,建议减少查询操作,用一次查询减少数据库的链接。重启后,第一次查询会比较慢,是因为要创建数据库连接池
- 多多使用grafana和Prometheus这种经典组合,以后其他公司也会用得着
本文作者:Eric
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!