请注意,本文编写于 712 天前,最后修改于 590 天前,其中某些信息可能已经过时。
目录
1.关于Rss的介绍
RSS(really simple Syndication)是一种消息来源格式规范,用以聚合经常发布更新数据的网站,例如博客文章、新闻、音频或视频的网摘。RSS文件包含了全文或是节录的文字,再加上发用者所订阅之网摘布数据和授权的元数据。
1.1 Rss的意义
对某一行业密切相关的几百个甚至几千个Rss的种子进行的聚合,将能快速、全面了解某一行的最新动态;对某一行业的几十个甚至几百个网站进行完整的数据下载,并进行数据挖掘,将能了解某一主题再该行业发展的来龙去脉。
1.2 运用
RSS在科研院所的应用。 高能物理信息监测对象为全球高能物理同行机构:实验室、行业学会、国际协会、各国主管科研政府机构、重点综合性科学出版物、高能物理试验项目和实验设施。监控的信息类型为:新闻、论文、会议报告、分析评论、预印本、案例研究、多媒体、图书、招聘信息等。
高能物理文献信息所采用最现金的开源内容管理系统Drupal,开源搜索技术Apache Solr,以及Google员工开发的能实时订阅新闻的PubSubHubbub技术和Amazon的OpenSearch,建立了一套高能物理信息检测系统,有别于传统的Rss订阅和推送,实现了几乎实时的信息抓取和任意关键词、任意类别、复合条件新闻的主动推送。
2. 网页搜索爬虫时效性系统
网页爬虫的目标:
- 覆盖率高
- 死链率低
- 实效性好 爬虫实效性的目标也差不多,主要是实现新网页快速和全面的收录。下图为时效性系统的整体架构:
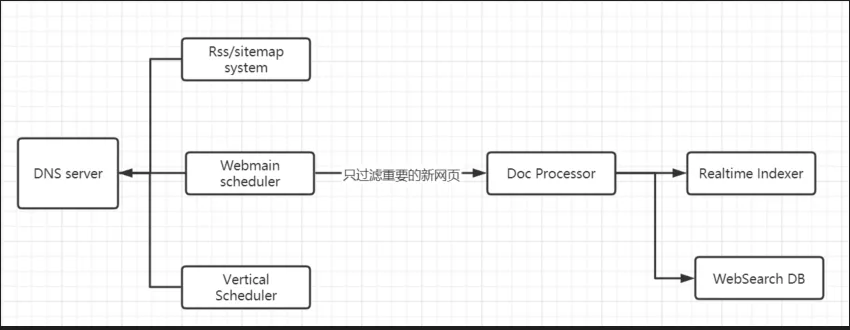
主要分为:
- Rss/sitemap子系统
- 网页泛爬的调度系统Webmain scheduler
- 时效性模块 Vertical Scheduler
- DNS服务,抓取的时候,一般是几十台甚至几百台抓取集群,如果每一台都有防御的话,对DNS的压力比较大,所以一般有一个DNS的服务模块来做全局的服务。
涉及到实效性的模块包括以下几个:
- Rss/sitemap系统:时效性系统利用Rss/sitemap的过程是挖掘种子,定时抓取,解析链接发布时间,将较新的网页优先抓取并索引。
- 泛爬系统:泛爬系统设计良好的话有助于提交时效性网页的高覆盖率,但泛爬需要尽可能缩短调度周期
- 种子调度系统:主要是一个时效性的种子库,这个种子库里面有一些信息调度系统会不断地扫描这个数据库,然后发给抓取集群,这个集群抓取完全进行一些抽取链接的处理,接下来把这些按类别发出去,各个垂直频道会获取到时效性的数据。
- 种子的挖掘:涉及到页面接卸或其他的一些挖掘手段,可以通过站点地图,还有导航条来构建,还要基于页面结构特征和页面百变得更规律
- 种子的更新机制:记录每个种子的抓取历史,follow的链接信息,定期根据种子的外链更新特征,重新计算种子的更新周期。
- 抓取系统与JavaScript解析:使用浏览器进行抓取,搭建一个基于浏览器抓取的抓取集群。或采用开源项目,如Qtwebkit。
帮助:
本文作者:Eric
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录