目录
What does a typical microservice architecture look like?
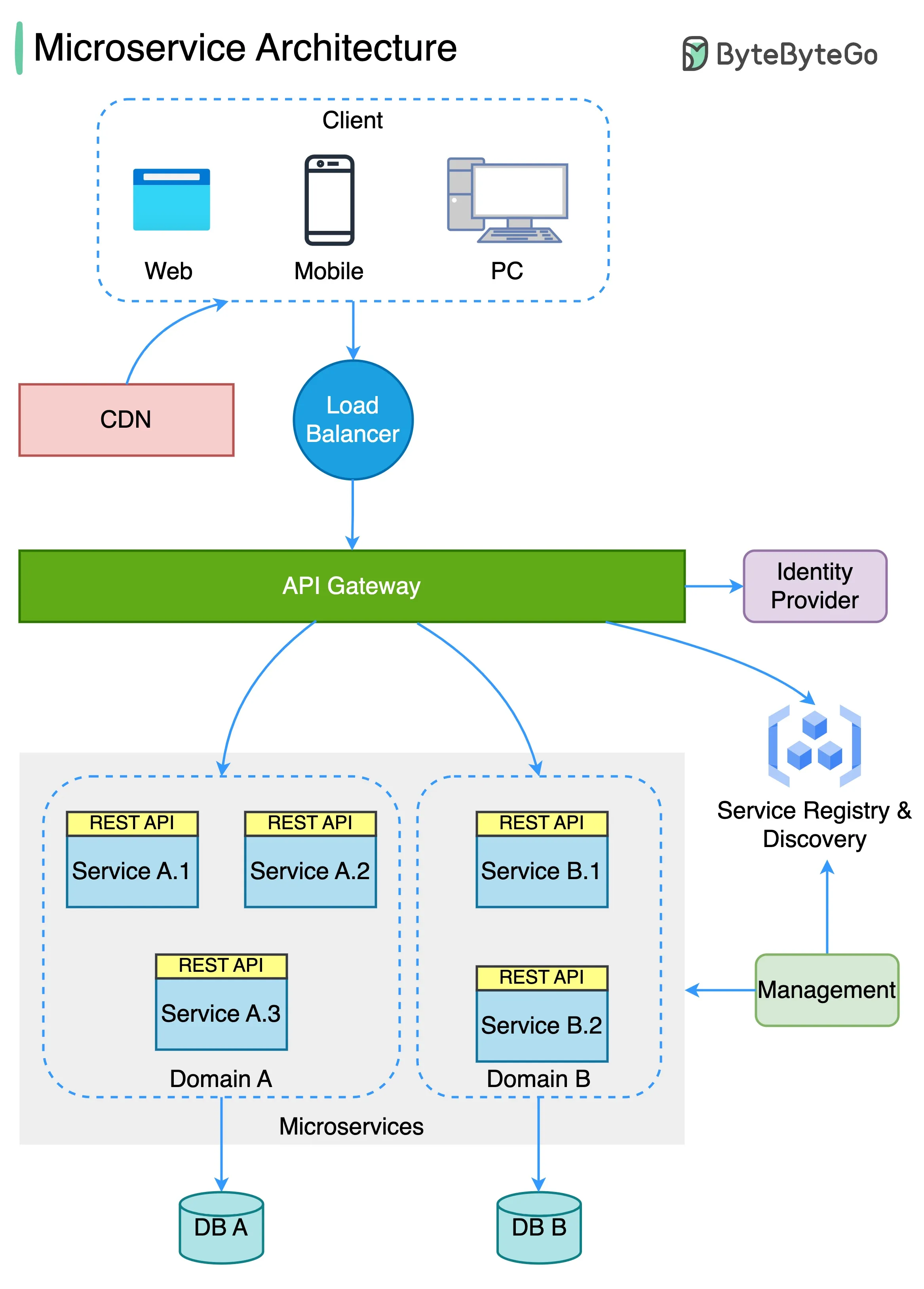
以下是一个典型的微服务架构示意图。
- 负载均衡器:这将传入流量分发给多个后端服务。
- CDN(内容分发网络):CDN是一组地理分布的服务器,保存静态内容以实现更快的交付。客户端首先在CDN中查找内容,然后转向后端服务。
- API 网关:这处理传入请求并将其路由到相关服务。它与身份提供者和服务发现进行通信。
- 身份提供者:这处理用户的身份验证和授权。
- 服务注册与发现:微服务的注册和发现发生在这个组件中,API 网关在这个组件中查找相关服务进行通信。
- 管理:这个组件负责监控服务。
- 微服务:微服务被设计并部署在不同的领域。每个领域都有自己的数据库。API 网关通过REST API或其他协议与微服务通信,同一领域内的微服务使用RPC(远程过程调用)相互通信。
微服务的好处:
- 它们可以快速设计、部署和水平扩展。
- 每个领域可以由专门的团队独立维护。
- 由于如此,每个领域的业务需求可以进行定制并得到更好的支持。
Microservice Best Practices
A picture is worth a thousand words: 9 best practices for developing microservices.
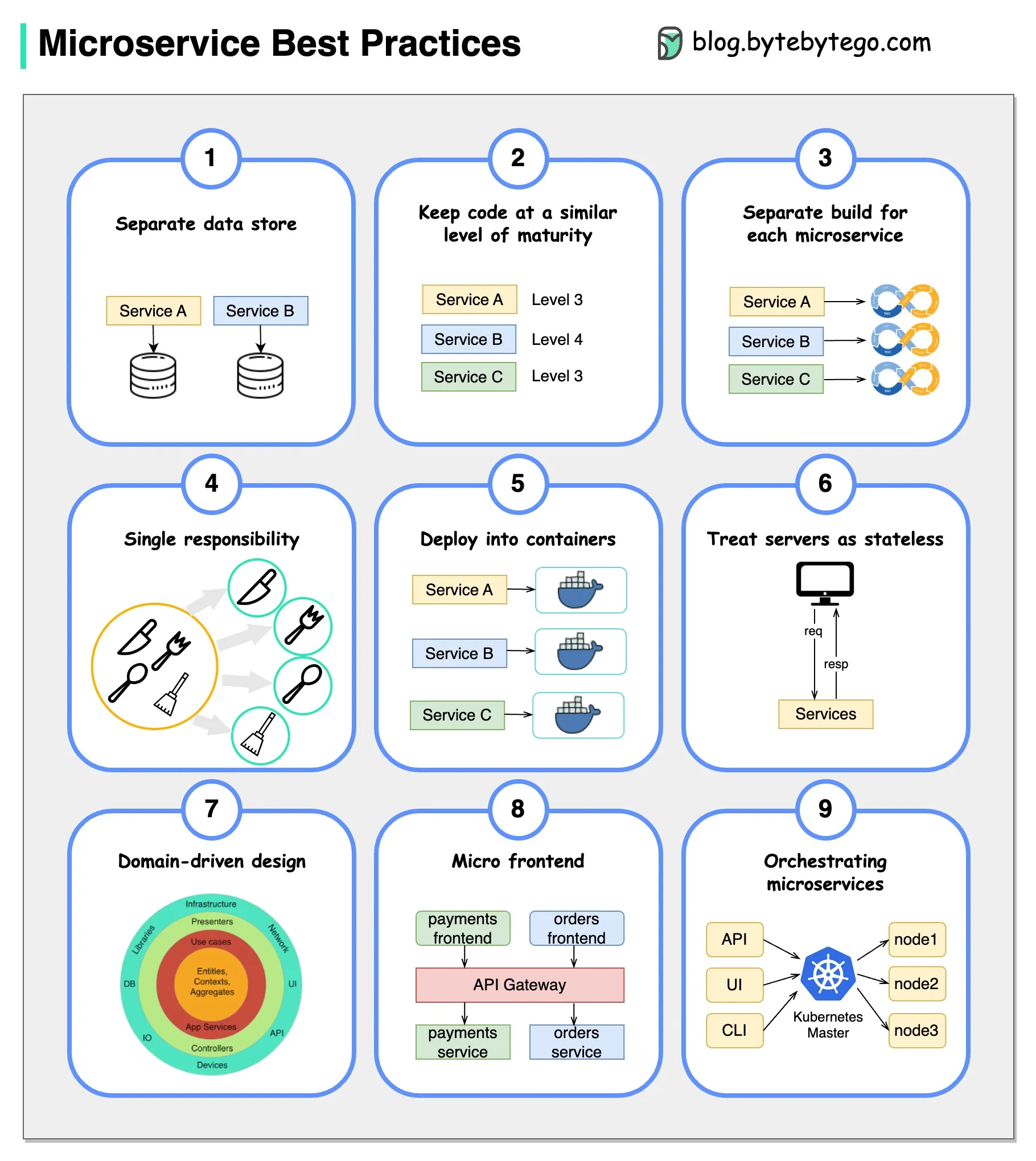
当我们开发微服务时,我们需要遵循以下最佳实践:
- 为每个微服务使用单独的数据存储
- 保持代码在相似的成熟水平
- 为每个微服务分别构建
- 将每个微服务分配给单一的职责
- 部署到容器中
- 设计无状态服务
- 采用领域驱动设计
- 设计微前端
- 编排微服务
What tech stack is commonly used for microservices?
Below you will find a diagram showing the microservice tech stack, both for the development phase and for production.
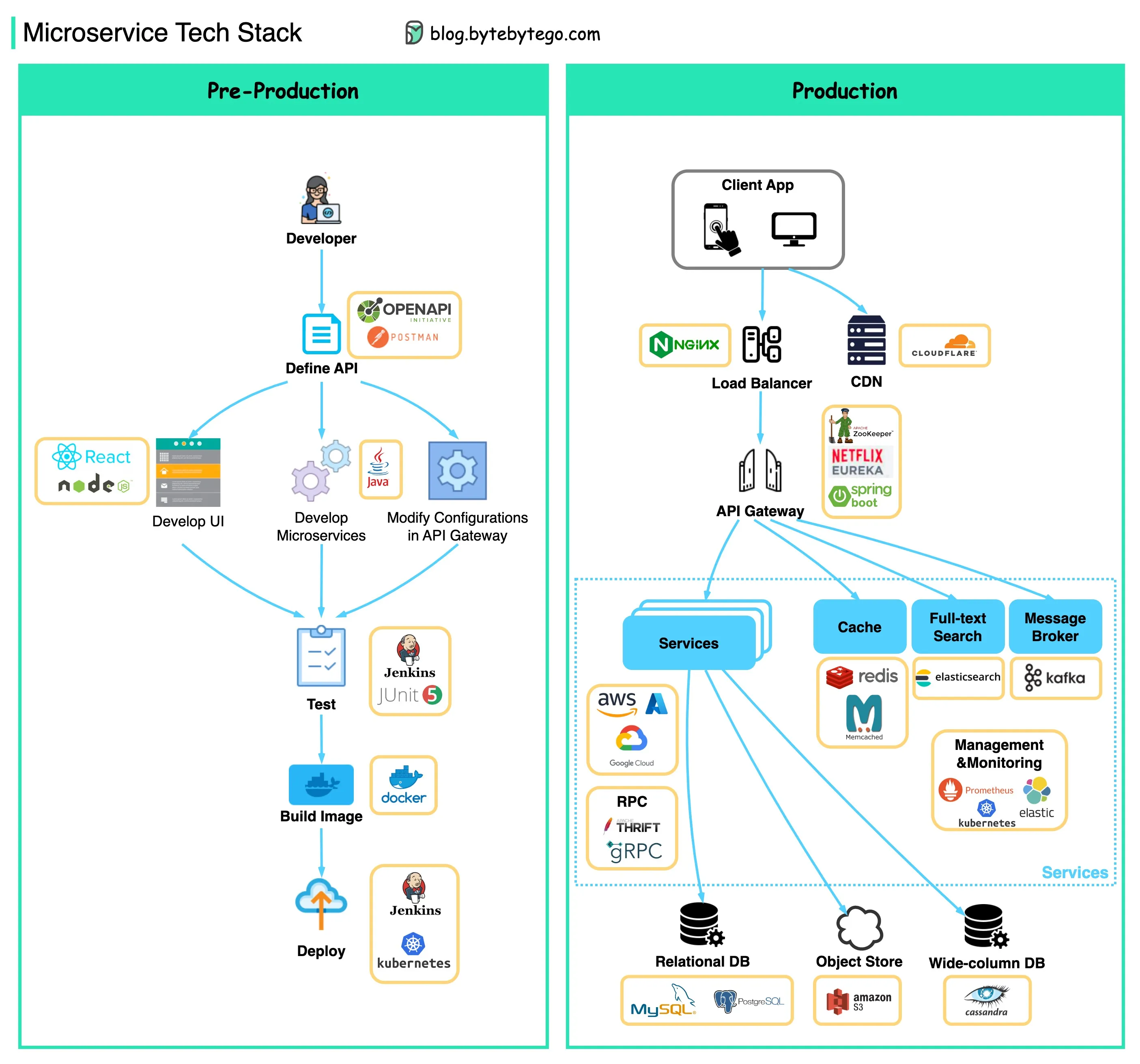
▶️ 𝐏𝐫𝐞-𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
- 定义 API - 这为前端和后端之间建立了合同。我们可以使用 Postman 或 OpenAPI 来实现这一点。
- 开发 - Node.js 或 React 在前端开发中很受欢迎,而 Java/Python/Go 则常用于后端开发。此外,我们需要根据 API 定义在 API 网关中更改配置。
- 持续集成 - 使用 JUnit 和 Jenkins 进行自动化测试。代码被打包成 Docker 镜像,并作为微服务进行部署。
▶️ 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
- NGinx 是负载均衡器的常见选择。Cloudflare 提供 CDN(内容传送网络)。
- API 网关 - 我们可以使用 Spring Boot 来构建网关,并使用 Eureka/Zookeeper 进行服务发现。
- 微服务部署在云上。我们可以选择 AWS、Microsoft Azure 或 Google GCP。缓存和全文搜索 - Redis 是缓存键值对的常见选择。Elasticsearch 用于全文搜索。
- 通信 - 为了让服务相互通信,我们可以使用消息基础设施 Kafka 或 RPC。
- 持久化 - 我们可以使用 MySQL 或 PostgreSQL 作为关系型数据库,使用 Amazon S3 作为对象存储。如果需要,我们还可以使用 Cassandra 作为宽列存储。
- 管理与监控 - 为了管理如此多的微服务,常见的运维工具包括 Prometheus、Elastic Stack 和 Kubernetes。
why is Kafka fast?
There are many design decisions that contributed to Kafka’s performance. In this post, we’ll focus on two. We think these two carried the most weight.
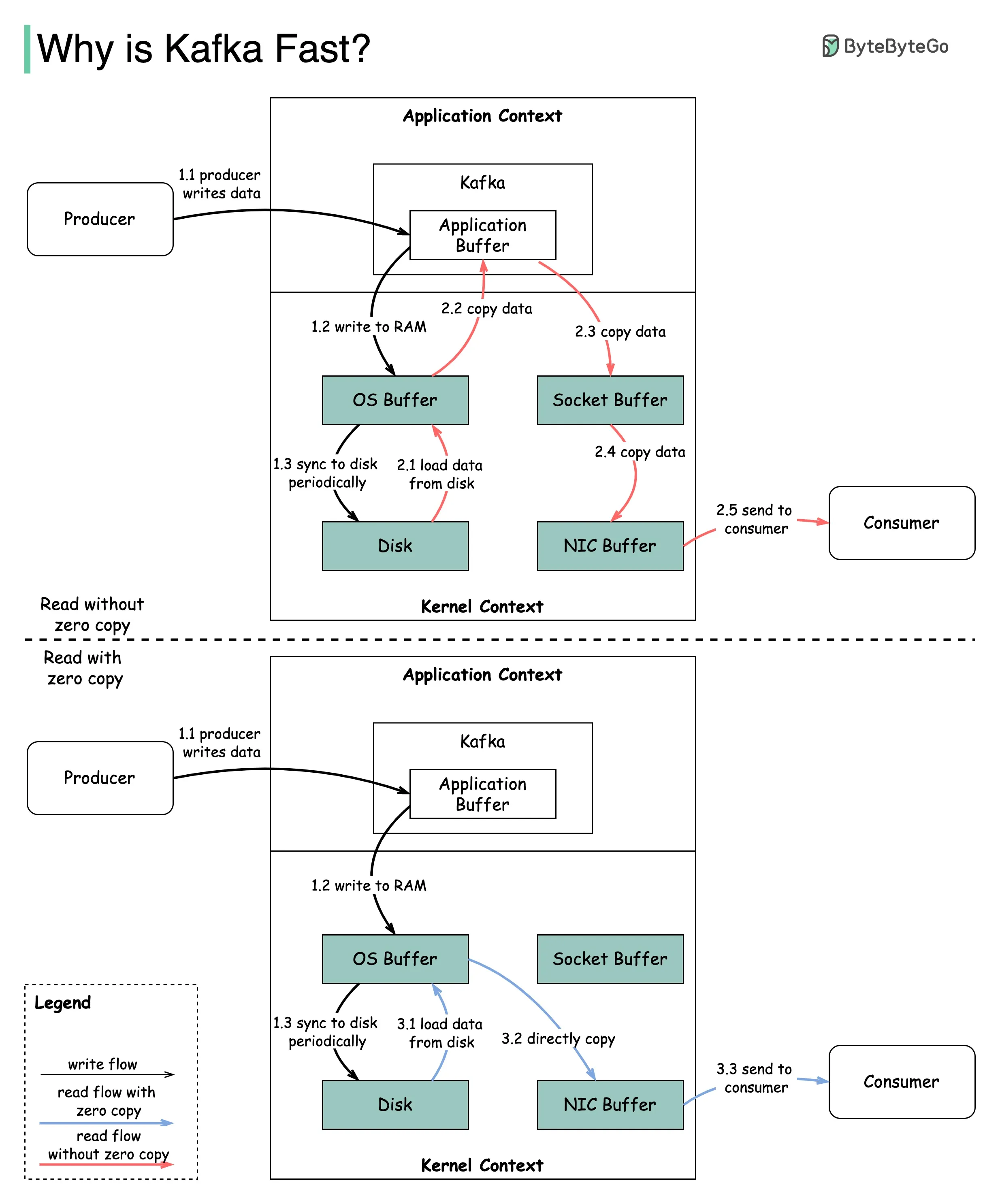
第一个是Kafka对顺序I/O的依赖。
赋予Kafka性能优势的第二个设计选择是其对效率的关注:零拷贝原则。 该图说明了数据如何在生产者和消费者之间传输,以及什么是零拷贝。
步骤1.1 - 1.3:生产者将数据写入磁盘
步骤2:消费者在不使用零拷贝的情况下读取数据
2.1 数据从磁盘加载到操作系统缓存
2.2 数据从操作系统缓存复制到Kafka应用程序
2.3 Kafka应用程序将数据复制到套接字缓冲区
2.4 数据从套接字缓冲区复制到网卡
2.5 网卡将数据发送给消费者
步骤3:消费者使用零拷贝读取数据
3.1:数据从磁盘加载到操作系统缓存
3.2 操作系统缓存通过sendfile()命令直接将数据复制到网卡
3.3 网卡将数据发送给消费者
零拷贝是一种捷径,用于节省应用程序上下文和内核上下文之间的多次数据拷贝。
本文作者:Eric
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!